
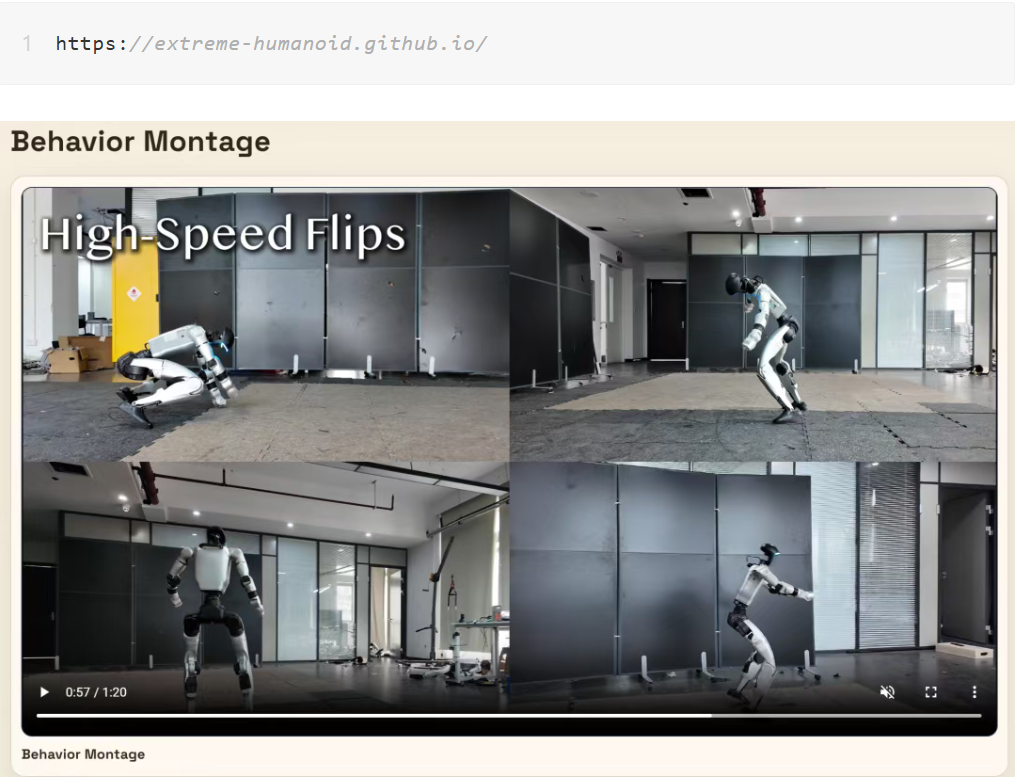
这套框架由宇树科技联合多家顶尖机构共同推出,不仅开放代码与模型,更提出了一套全新的运动生成范式:不再把动作拆成片段拼接(离散型,动作僵硬、卡顿),而是学习一个统一、全域、连续的动作流场(连续型,动作更丝滑)。而让这一切成为可能的核心,就是Flow Matching(流匹配)算法。


这是一篇来自宇树科技、北京通用人工智能研究院等多家联合团队的人形机器人控制顶会论文(2026),核心突破是打破高动态人形控制的通用性瓶颈,让一个策略模型能同时完成极端平衡、多样化行为、极限速度、接触交互四大类高难度任务。如图1所示,就是让同一个策略模型(Unified Policy),同时能模拟多类动作输出(Diverse Behaviors),做到了策略层面的统一,不再是每个动作配置单独的策略。
这个模型的核心仍然是基于Transformer架构,具体是Transformer编码器-解码器(Encoder-Decoder)结构,并结合了时序建模与多模态特征融合。用Transformer架构去参数化Flow Matching中需要拟合的核心函数(流场、策略网络等),让Flow Matching借助Transformer的强大特征能力,更好地学习和生成动作。说白了,就是用Transformer把Flow Matching算法的思想落地,这样做会带来很多好处,下文会有详细的讲解。
(一)人形机器人动作为什么天生 “僵硬、卡顿、抖”?4大痛点
1.动作是离散的,不是连续的
绝大多数传统方案,都遵循同一种逻辑:先定义动作类别,再为每个动作生成轨迹,最后在动作之间做切换。
走路是一套策略、跑是一套策略、跳是一套策略、空翻是另一套策略。机器人就像一个 “动作库播放器”,执行时需要先决策 “我现在该播放哪一段动作”,再从库中调取预先生成的轨迹。
这样会带来两个比较明显的问题:
(1)以单个动作为粒度太粗:导致动作之间硬切换,出现断层、卡顿、抖动;
(2)动作数量越多,策略越混乱,越难保证稳定,而且策略之间很可能互斥。
2. 控制的目标或者说粒度是单个点,而不是流Flow
传统机器人控制,无论是关键帧插值、轨迹优化、MPC模型预测控制,还是早期单任务强化学习,本质都在做同一件事:求解下一时刻的目标姿态、目标位置。
系统先算出若干关键姿态点,再在点与点之间做直线或曲线插值(Interpolation),最后下发给电机执行。这种点到点之间的控制方式,像极了提线木偶:位置精准,但运动生硬、缺乏惯性、缺乏流畅度。
举个具体的例子,假如机器人当前状态是蹲在地上,下一个动作是要站起来,如果是按照“点到点”的逻辑,机器人从蹲着到站起来就是一个动作,没有中间状态,你会看到机器人站起来的动作非常生硬;而基于流Flow的模式就不一样,它会告诉机器人以每秒多少米的速度站起来,这样你会看到机器人站起来的过程是非常连续的、丝滑的,这就是下面要讲的Flow Matching算法的效果,让机器人动作连续,这样机器人跳舞才好看,动作才更像人类!
3.仿真很丝滑,真机严重割裂
在仿真环境里,机器人可以做到完美空翻、高速运动,但一旦部署到真实硬件,立刻出现抖动、漂移、功率超限、甚至摔倒。
原因其实也很简单:仿真环境经常忽略了电机扭矩限制、转速包络、摩擦、时延、惯性、反电动势等真实物理特性。导致仿真里的“丝滑”,在真机里根本跑不出来。
4.多个动作泛化能力极差
传统框架很难让机器人同时学会“跑、跳、空翻、旋转、舞蹈、平衡” 等一系列高动态技能。因为不同任务的优化目标冲突、奖励信号冲突、梯度方向冲突,最终导致:学得越多,表现越烂。
这就是人形机器人领域长期存在的通用性壁垒:稳定与灵活难以兼顾,单一与通用难以共存。
OmniXtreme要做的,就是彻底打破这堵墙。实际上OmniXtreme不再以最终动作为粒度了,策略不再是预测下一个动作是跑、跳、还是空翻,而是输出机器人各个关节、组件下一时刻(比如20ms之后)的速度和方向,让这些关节的动作组合(流式Flow)形成一个统一的效果,这样粒度就更细、更丝滑了!
(二)OmniXtreme框架
在这里再强调一下OmniXtreme的技术细节,方便大家快速理解下面的内容,还是上面的例子,假设机器人从蹲着到站起来需要1秒的时间,那么在这1秒内传统的方式可能会通过插值方式来补充中间动作,而OmniXtreme用到的Flow算法是则是采用流式处理,比如每20毫秒输出整组各个关节下一步的速度和方向,也就是1秒内可以输出大约50个“中间结果”,也就是50个精细指令,那动作看起来自然就很流畅。
所谓流式,是一个效果概念,从机器人的动作效果看,它很丝滑,很流式!但不是数学上无限连续,而是把时间切得极细、逐帧逐时刻实时计算。因此Flow Matching算法也要分段处理,按帧、按时刻t等,只是说这个间隔很小。熟悉大数据Flink算法的同学,应该马上就能理解,经常提到的流式处理,流批一体,都是类似的。
1.)OmniXtreme四大目标:通用性 + 流畅性 + 鲁棒性 +连续性
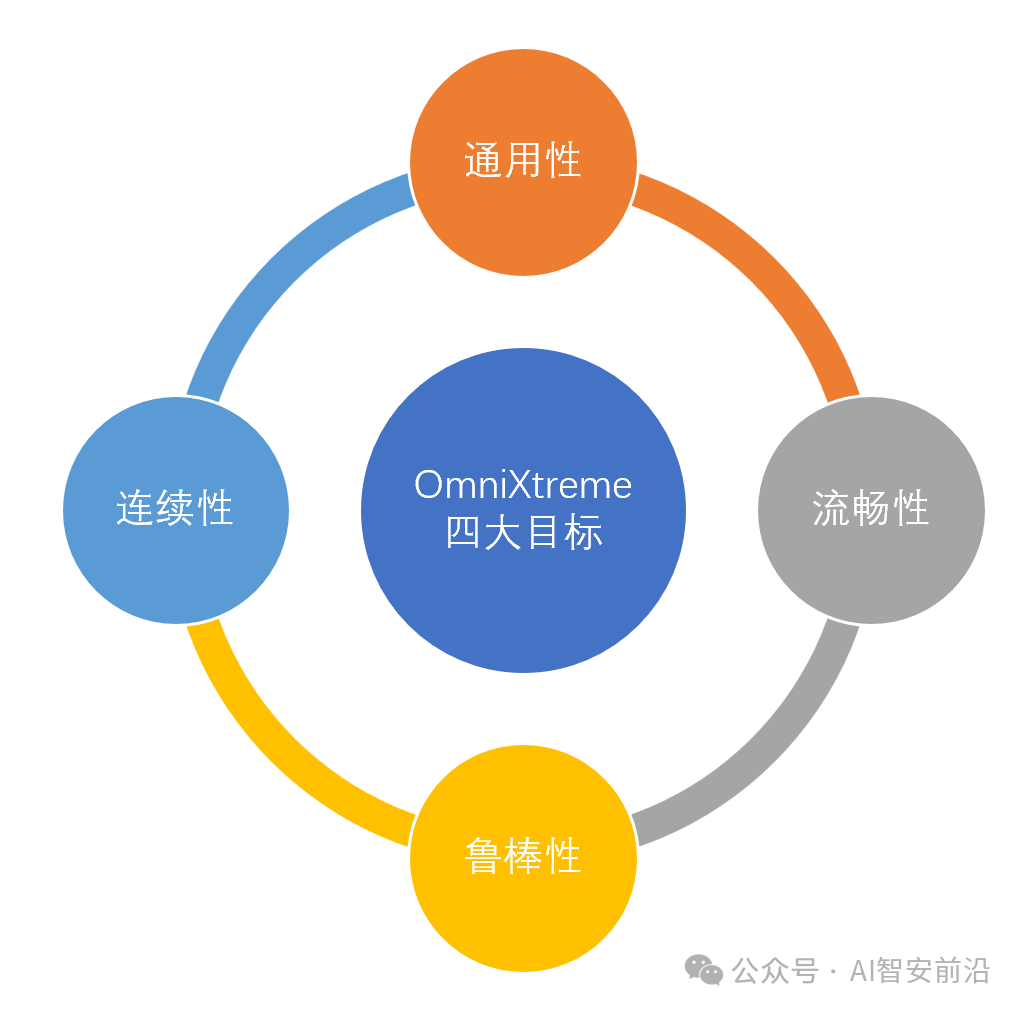
(1)通用性:让机器人学会海量高动态动作(通过流来学习,动作只是结果);
(2)流畅性:让动作极度连贯、丝滑、自然;
(3)鲁棒性:让仿真策略可以稳定落地到真机;
(4)连续性:让多动作之间无切换、无断层、不打架。
2.)OmniXtreme双阶段训练范式
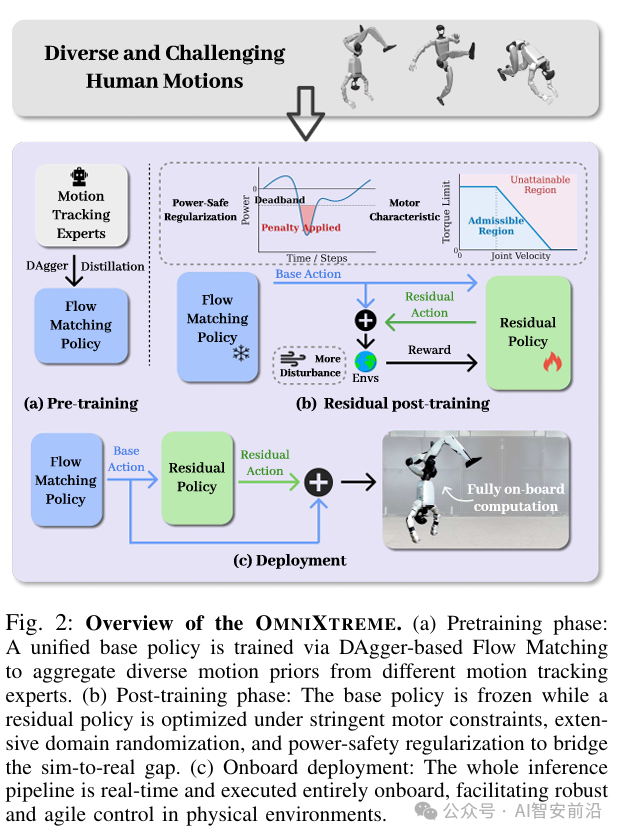
如图3所示,OmniXtreme为了解决上面提到的传统机器人痛点,提出了一个两阶段训练框架,专门解决人形机器人高保真、可扩展的运动技能学习问题,核心是让机器人在真实世界里也能做出流畅、鲁棒的复杂动作。整体流程分为以下三大模块:
(1)Pre-training:Flow Matching统一流场预训练
用Flow Matching算法,从多样化专家策略中蒸馏出一个统一的基础策略Basic-Policy,建立跨动作的共享跟踪先验,最终学习一个覆盖所有动作的连续向量场。
这里的“Flow Matching”指的是机器人的动作流和专家的动作流之间的匹配,匹配度越高,说明机器人学习专家的动作越准确,越丝滑。简单来说,虽然我们的训练数据是来自专家策略的离散动作样本,但Flow Matching学习的并不是这些离散点本身,而是建立一个连续的速度场(Velocity Field),这个速度场定义了从随机噪声到专家动作的连续流(听起来是不是和Diffusion有点像,只能说优秀的思想常用熟悉的套路)。
关于参考动作Mi
就是来自专业动作捕捉数据集(如LAFAN1、AMASS等)的专家动作序列,代表了高质量、多样化的人类运动模式,论文里提到了一个词就是DAgger(Dataset Aggregation)。
针对每一个专家参考动作Mi,通过PPO(近端策略优化)训练一个对应的专家策略π-expert-i(a∣o),这个策略的目标就是精确复现该专家动作。然后,再通过Flow Matching算法,将这些针对不同动作的专家策略,蒸馏成一个统一的流匹配策略πθ(a∣o),从而让机器人具备泛化到新动作的能力。
这里稍微补充一下,所谓策略,就是一个概率分布(在当前状态下,生成下一个动作的概率分布)。虽然每个专家动作的策略是离散的,但Flow Matching是把所有离散的专家动作策略做了统一融合,基于这个统一策略,生成连续的动作。
Flow Matching的核心价值,就是把“为每个动作单独训练一个策略” 的低效方式,升级为 “用一个统一策略处理所有动作” 的高效方式,这正是其可扩展性和泛化能力的关键。
(1)Post-training:残差强化学习训练,解决Sim-to-Real Gap
冻结基础策略,训练一个残差策略,通过RL强化学习来补偿仿真与现实的差距,适配真实硬件约束。
(2)Deployment:部署阶段
整个推理管线完全在板上实时运行,保证物理环境下的鲁棒控制。
1.全板载计算
整个推理管线(基础策略 + 残差策略)都在机器人板上实时运行,不依赖外部计算。
2.实时性
控制频率高(约50Hz),保证在物理环境中敏捷、鲁棒的控制。
3.优势
减少通信延迟,提升在复杂、动态环境中的响应速度和稳定性。
(三)Flow Matching算法
这是本篇比较难的部分,但是有了上面那么多技术铺垫,应该好理解一些了。首先,“Flow Matching”名字的含义是两个流在做Matching,也就是让机器人的动作流和专家的动作流去匹配,让相似度尽量高,效果才好。其次,在Flow Matching眼里,是没有最终动作的,例如跑、挑、翻身等,而是整组关节的下一个时刻的速度和方向,也就是论文里常说的流量场概念。
想像一下,Flow Matching就好像通过统一策略输出机器人每隔20ms整组关节的速度和角度,不断的输出,机器人不断的执行,让人看到的就是非常连续、丝滑的动作流,至于第3秒的动作是跑,第5秒的动作是后翻身,这些都是结果,不是目的,对于Flow Matching来说都是透明的,你看到的只有一个,就是机器人不断输出的动作流。
1.)流匹配策略
不是规则,不是轨迹,不是调度器,而是一个神经网络,就是文章开头提到的Transformer,也就是说Flow Matching的算法实现是基于Transformer的。神经网络的方程就是vθ(x,t),其中
a.vθ:向量场网络,也就是策略网络π_θ;
b.x:机器人当前状态;
c.t:流的时间参数(0~1);
d.θ:网络参数,或者说策略参数;
2.)输入:x,机器人当前的全局状态
a.所有关节角度;
b.所有关节速度;
c.躯干姿态(滚转、俯仰、偏航);
d.躯干角速度;
e.足端接触状态;
3.)输出:整组关节的动作指令,用一个统一的高维向量来包含所有
a.髋关节以多少度/秒旋转;
b.膝关节以多少度/秒弯曲;
c.踝关节以多少度/秒运动;
d.所有关节的速度指令;
2.)Flow Matching Policy Learning

图4主要展示了Flow Matching的损失函数,一个算法如果看懂了损失函数也就看懂了算法最核心的部分。
其中a代表action,o代表观察状态,这里指的是Trajectory运动轨迹,t是时间,ϵ是随机噪声,vθ就是策略πθ。
构建带噪声的动作轨迹
对于每个专家动作aexpert,在时间步t∈[0,1]上构建一条带噪的插值轨迹,其中ϵ∼N(0,I) 是随机噪声。这条轨迹连接了t=1时的纯噪声a1=ϵ和t=0时的专家动作a0=aexpert。
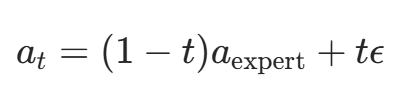
稍微补充一下,这里把时间步t限制在[0,1],本质上是为了把“从噪声到专家动作”的整个生成过程,归一化成一个从0到1的连续流,方便统一建模和训练,其中a1是起点,a0是终点,at就是中间过渡过程中的点。
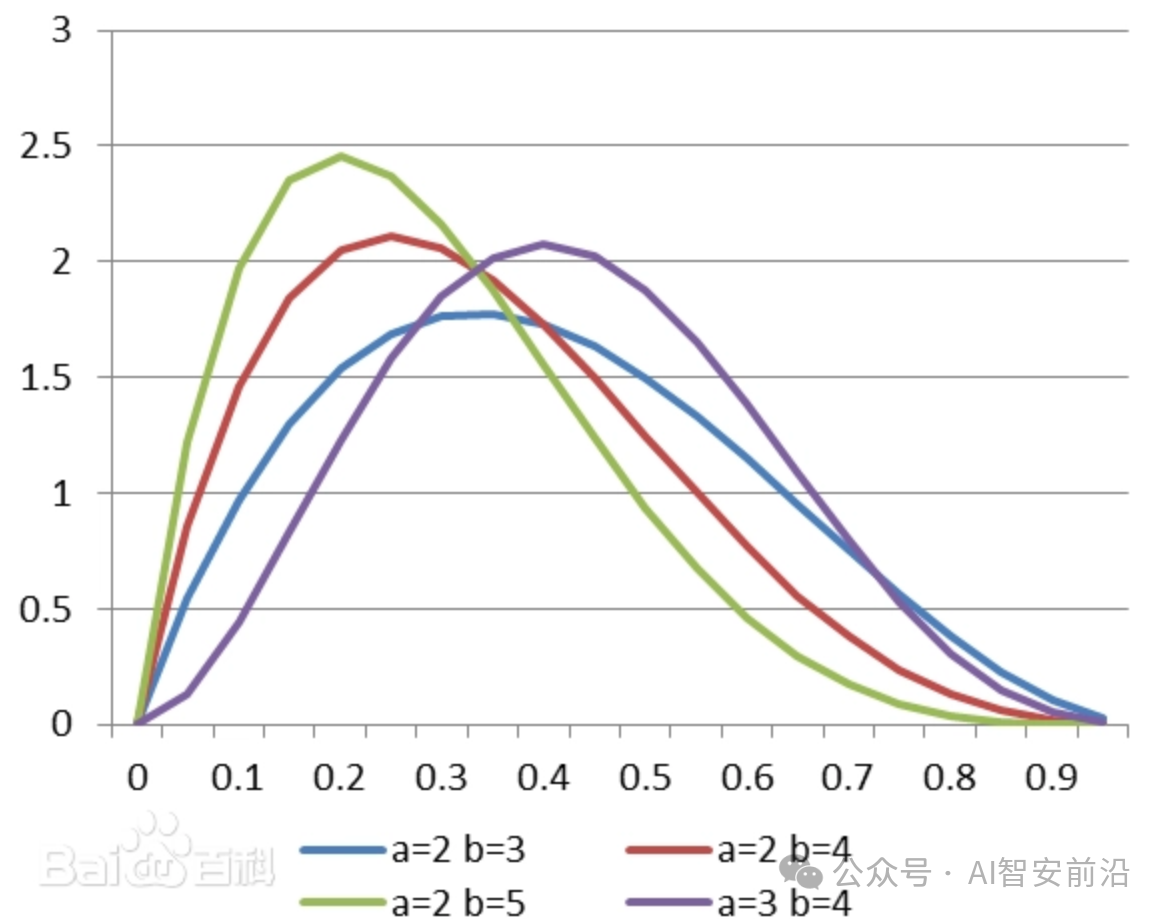
在训练过程中,需要在0和1之间进行采样,论文里提到用Beta分布即t∼Beta(α,β),这是为了让模型更关注流的关键区域(比如靠近t=0的区域,因为这里更接近专家动作,对生成质量影响更大),从而提升收敛性和轨迹精细度。我找一张Beta分布的图,大家一看就懂了,明显重心偏左侧。
学习速度场vθ
模型的目标是学习一个速度场 vθ(at,t,o),它能预测出在当前状态o、带噪声动作at和时间步t下,下一步应该向哪个方向“流动”才能更接近专家动作。这个方向就是目标速度u=ϵ−aexpert。这个损失函数迫使模型学习到一个连续的、平滑的去噪方向场。
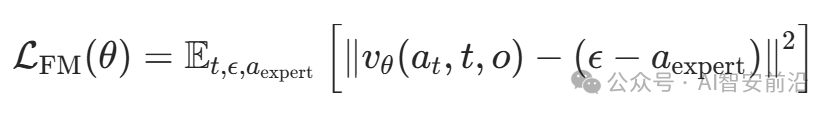
关于目标速度u=ϵ−aexpert,这个其实就是一个非常简单的求导,我们看上面的运动轨迹公式at = (1 - t)aexpert +tϵ,那就意味着基于这个运动轨迹去预测未来动作流的方向,需要对at进行求导,求导公式如下,这个导数就是从at流向a0的真实方向。模型的目标就是学习一个速度场vθ,去拟合这个真实的导数。所谓速度场vθ就是有大小,有方向的矢量。Loss就是vθ和u这两个高维向量之间的欧氏距离平方,越近越好。
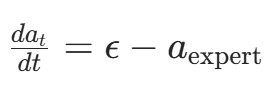
生成精细动作
一旦学会了这个连续的速度场vθ,我们就可以通过数值积分(如前向欧拉法)从随机噪声a1=ϵ出发,逐步“流”向目标动作a0。
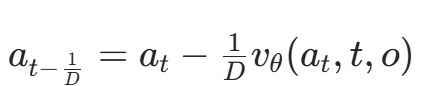
这里的D是积分步数,也就是我们之前提到的 “中间结果” 数量。通过设置D=50,我们就能在1秒内生成50个精细的中间动作(其实也可以理解成50Hz),从而实现流畅的动作控制。
这其实就是一个积分过程,具体如下,这样做的好处是每一步的预测动作都很丝滑,是经过导数计算出来的,不是通过固定插值方式填充的。
1.从t=1(纯噪声a1=ϵ)开始。
2.每一步,我们根据当前的带噪声动作at、时间步t和观测o,用速度场 vθ预测下一步的流动方向。
3.沿着这个方向,以步长1/D向前推进,得到下一个时间步的动作 at−1/D。
4.重复这个过程D次,最终到达t=0,得到目标动作a0。
总结一下,其实Flow Matching算法干的活和传统插值法(Interpolation)是非常类似的,只是要比插值法更丝滑,具体对比如下:
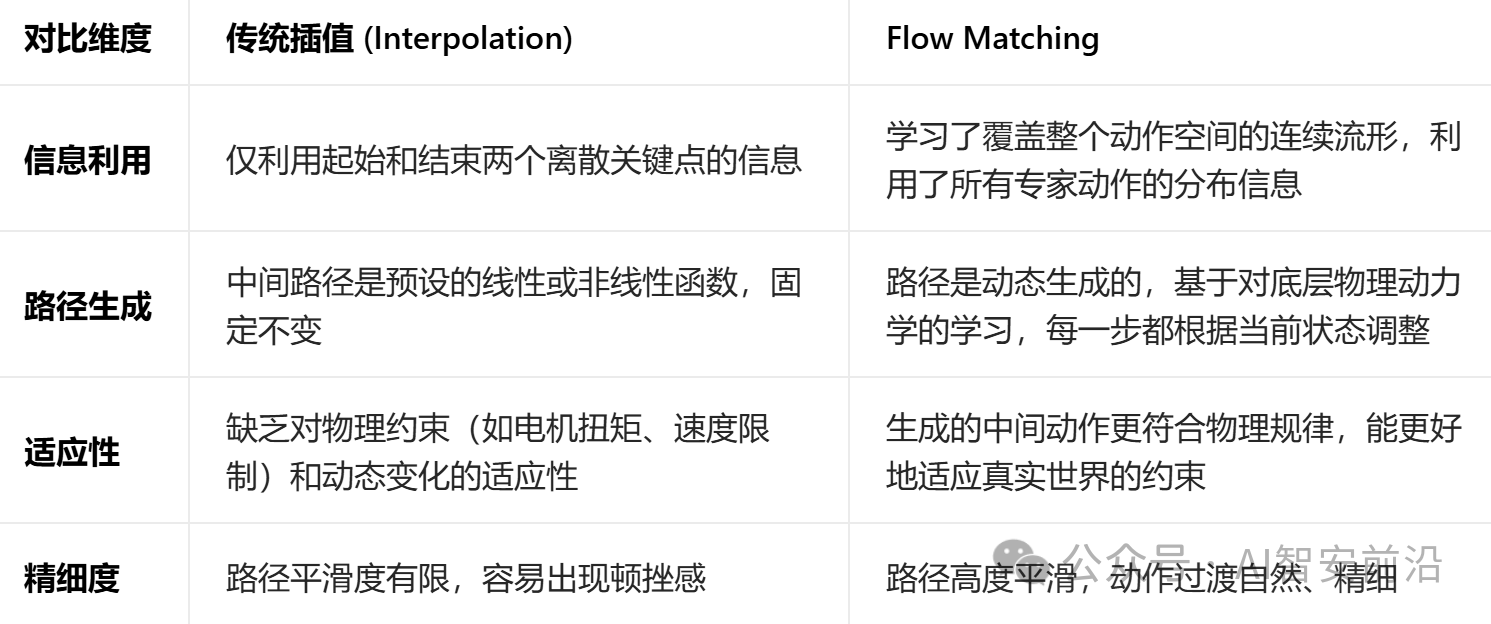
1.传统插值
是在两个已知的离散关键点(如起始和结束动作)之间进行线性或非线性插值,它只利用了这两个点的信息,中间的路径是预设的,缺乏对物理约束和动态变化的适应性。
2.Flow Matching
学习的是一个覆盖整个动作空间的连续流形。它不仅知道最终的专家动作,还知道从任何一个带噪状态出发,如何一步步、平滑地过渡到目标动作。这个过程是基于对底层物理动力学的学习,因此生成的中间动作更符合物理规律,也更精细、更自然。
好,我们对OmniXtreme和Flow Matching算法的讲解就差不多了,Flow Matching最大的特点是即使训练数据是离散的,仍然能通过学习连续的速度场,实现了从“点”到“流”的升级,从而保证了策略的精细度和流畅性。所以,目前的机器人在Flow Matching算法加持下,动作会越来越丝滑,但是仍然是在有监督的学习范畴,希望未来的机器人更加的智能,更有创造性!
 京公网安备11010502056287号
京公网安备11010502056287号