
1. 早期萌芽(1940s-1980s)
1943年:Warren McCulloch 和 Walter Pitts 提出首个人工神经元模型,奠定了神经网络的理论基础。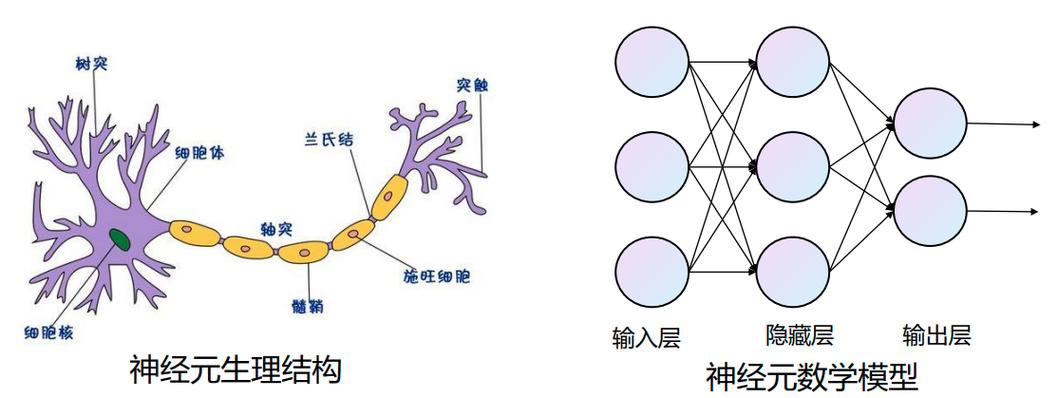
1958年:Frank Rosenblatt 发明感知机(Perceptron),首次实现可训练的神经网络,用于简单分类任务。
1969年:Marvin Minsky 和 Seymour Papert 在《Perceptrons》一书中指出感知机的局限性(无法处理异或问题),导致神经网络研究进入第一次寒冬。
2. 复兴与突破(1980s-2000s) 1986年:Geoffrey Hinton、David Rumelhart 等人提出反向传播算法(Backpropagation),解决了多层神经网络的训练问题。
1989年:Yann LeCun 提出卷积神经网络(CNN),成功应用于手写数字识别(LeNet-5)。
1997年:Hochreiter 和 Schmidhuber 提出长短时记忆网络(LSTM),解决了传统RNN的梯度消失问题。
2006年:Geoffrey Hinton 提出深度信念网络(DBN),标志着深度学习的正式诞生,开启了多层神经网络的训练新时代。
3. 深度学习爆发(2010年代)
关键事件:
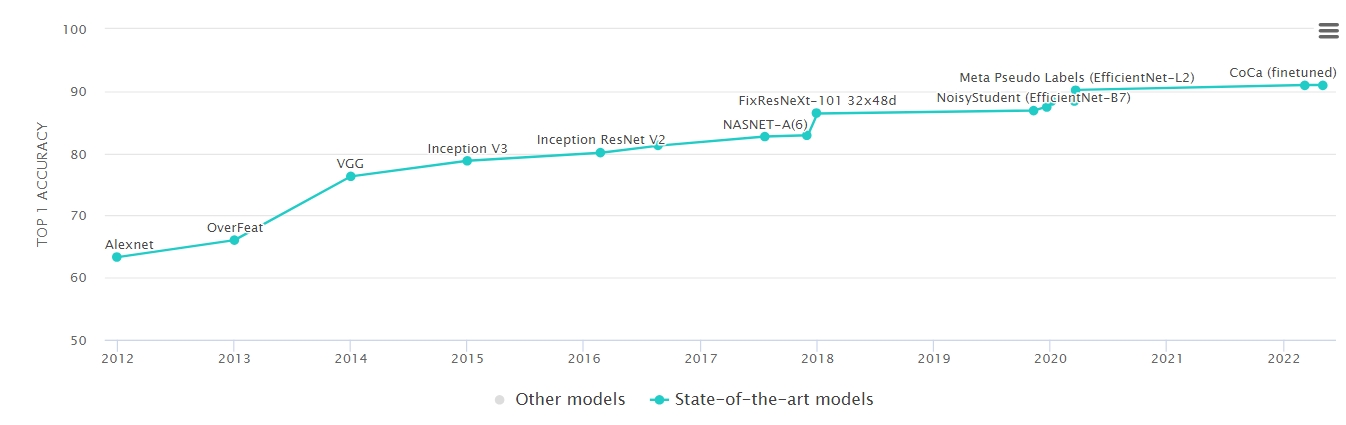
2012年:AlexNet 在 ImageNet 图像分类竞赛中击败传统方法,错误率从26%骤降至15%,震惊学术界。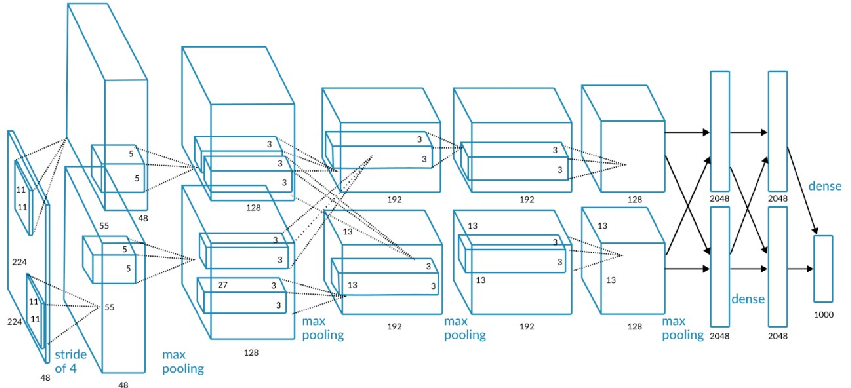
技术突破:使用 GPU 加速训练、ReLU激活函数、Dropout正则化。
意义:证明了深度学习的潜力,引发工业界关注。
2014年:生成对抗网络(GAN) 提出(Ian Goodfellow),开启了生成模型的新方向。Google收购DeepMind,强化学习(如AlphaGo)成为焦点。
2015年:ResNet(残差网络)在ImageNet上实现超越人类的分类精度(错误率3.57%)。TensorFlow 开源,降低深度学习开发门槛。
2016年:AlphaGo 击败李世石,成为人工智能的“标志性事件”,引发全球媒体热议。
2017年:Transformer 架构提出(《Attention Is All You Need》),彻底改变了自然语言处理(NLP)。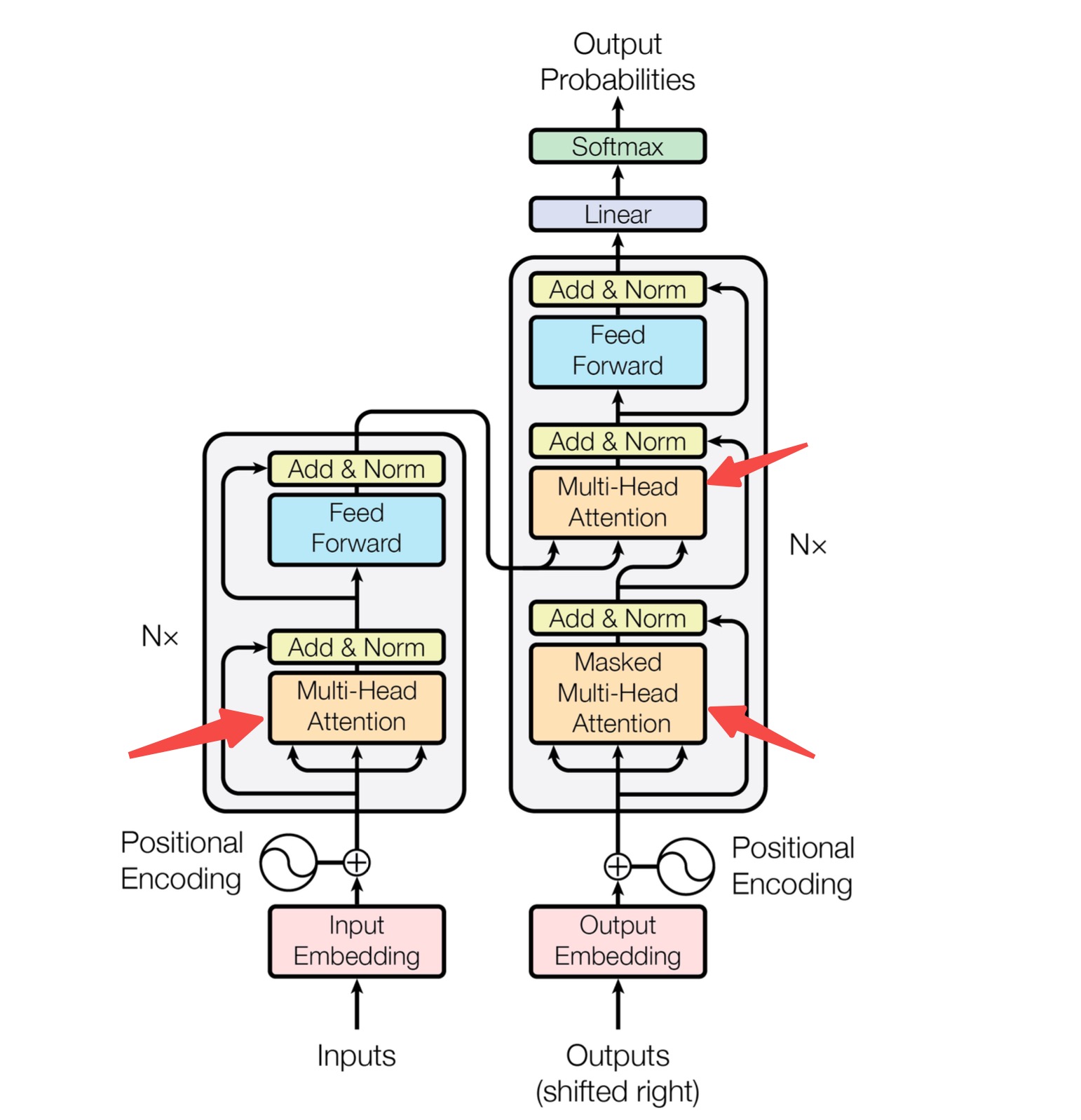
PyTorch 发布,动态计算图特性使其成为研究首选框架。
4. 大规模应用与生态成熟(2020年代) 2020年:GPT-3 发布(1750亿参数),展示了大语言模型的强大能力。
2022年:Stable Diffusion 和 DALL·E2 推动生成式AI普及,图像生成进入大众视野。
2023年:ChatGPT 引爆全球,AI进入“大模型时代”,技术渗透到搜索、办公、教育等领域。

2025年:DeepSeek 横空出世,以其低成本与开源,让近乎所有人疯狂,普通人也可以近距离拥抱AI技术。
推动热潮的核心因素 算力革命:
GPU并行计算(NVIDIA CUDA生态)大幅加速训练。
云计算(AWS、Google Cloud)提供弹性算力。
数据爆炸:
互联网产生海量数据(ImageNet、社交媒体文本、视频等)。
数据标注产业成熟(如亚马逊Mechanical Turk)。
算法进步:
激活函数(ReLU)、正则化(Dropout)、归一化(BatchNorm)等技术解决了训练难题。
自监督学习、对比学习(如SimCLR)减少对标注数据的依赖。
开源生态:
框架(TensorFlow、PyTorch)、预训练模型(Hugging Face)、数据集(Kaggle)降低了技术门槛。
资本与需求驱动:
科技巨头(Google、Meta、OpenAI)投入巨资研发。
行业需求(自动驾驶、医疗影像、金融风控)推动技术落地。
5. 未来的挑战与方向 算力与能效:大模型的训练成本(如GPT-4耗资数千万美元)和碳足迹问题。
可解释性:神经网络仍是“黑箱”,缺乏理论支撑。
伦理与安全:生成式AI的滥用(Deepfake、虚假信息)。
边缘计算:轻量化模型(如TinyML)在移动端的部署。
神经网络算法从理论探索到全球热潮,经历了80年的曲折发展。2012年的深度学习突破是关键的转折点,而算力、数据、算法的协同进化最终推动了这场技术革命。如今,神经网络已成为人工智能的核心引擎,正在重塑人类社会的信息处理方式。
 京公网安备11010502056287号
京公网安备11010502056287号