
为了转向统一的多模态理解和生成框架,目前存在两个基础性的关键问题:
1、如何赋予多模态理解模型生成图像的能力?这通常需要精心设计一个能够与大型多模态语言模型无缝协作的视觉解码器。
2、如何有效地在理解和生成任务上训练统一模型?我们观察到,GPT-4o通过整合图像生成能力进一步提升了理解能力,暗示统一训练可能协同提高模型在多个任务上的表现。
针对这些基础问题,阿里巴巴国际化数字商业集团AI Business 多模态团队,基于自主研发的Ovis(Open Vision models)基础模型,推出了统一的多模态理解与生成模型:Ovis-U1。
Ovis-U1作为Ovis家族的系列模型之一,在模型架构侧结合了基于扩散的视觉解码器和双向令牌细化器,使得模型具备生成高保真图像的能力。同时Ovis-U1采用了全新的统一训练方法,仅由语言模型初始化,从头训练模型的视觉理解和视觉生成的能力,在理解和生成任务中找到了协同增强的路径。
测评结果显示,在同级别参数量(~3B)下,相比于主流开源模型,Ovis-U1模型在多模态理解评测榜单、文生图评测榜单、图像编辑评测榜单上取得SOTA结果。并且对于Ovis-U1模型和评测代码,实现完全开源,开源信息如下:
(1)技术报告:https://arxiv.org/pdf/2506.23044
(2)代码:https://github.com/AIDC-AI/Ovis-U1
(3)模型:https://huggingface.co/AIDC-AI/Ovis-U1-3B
(4)Demo:https://huggingface.co/spaces/AIDC-AI/Ovis-U1-3B
Ovis-U1继承了Ovis的架构,并通过增加视觉解码器以生成图像。这个统一模型不仅能够理解输入的图像和文本,还能生成图像和文本,实现多模态理解生成一体化模型。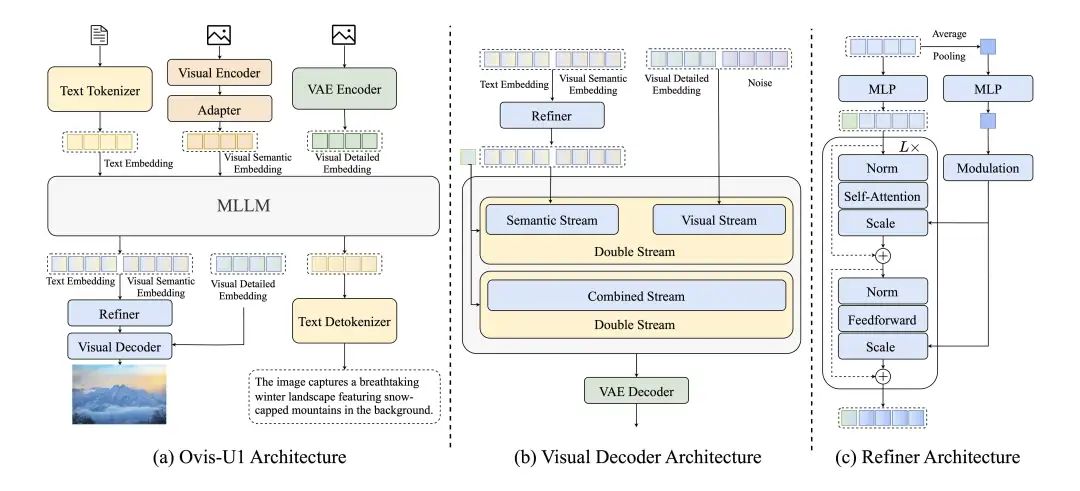
大语言模型(LLM)与文本分词器
我们采用Qwen3系列作为Ovis-U1的骨干模型。具体的,我们选择Qwen3-1.7B来创建具有30亿参数的Ovis-U1模型。与以往直接使用多模态大语言模型的方法不同,Ovis-U1从语言模型初始化,通过视觉理解和生成数据训练,以同时增强其在理解和生成任务中的性能。
视觉编码器(Visual Encoder)与适配器(Adapter)
我们对Ovis原有的视觉编码器进行了增强。新的视觉编码器基于Aimv2-large-patch14-448初始化,能够原生处理任意分辨率的图像。通过插值调整原有固定大小的位置信息嵌入,并引入2D旋转位置信息嵌入(RoPE)以提升空间感知能力。架构采用了可变长度序列注意机制,结合NaViT的令牌打包策略,高效处理不同分辨率图像的训练批次。随后,视觉适配器通过像素混洗操作进行空间压缩,结合线性头和softmax函数,将特征转换为视觉词汇的概率分布,最终传输至LLM。
视觉解码器(Visual Decoder)与VAE
视觉解码器使用扩散变换器。受FLUX的启发,我们采用MMDiT+RoPE的模型结构,通过缩减层数和注意头数,形成1B参数的视觉解码器。通过使用SDXL的VAE模型将原始图像像素空间转换至隐空间,并在训练中将其冻结。视觉语义嵌入与文本嵌入拼接,为生成图像提供语义条件。同时,我们使用VAE编码输入图像的细节特征,提升模型做图像编辑任务时的细节保持能力。
细化器(Refiner)
通过引入双向令牌细化器,以促进视觉嵌入和文本嵌入之间的交互。通过两层变换器模块使得不同层次的图像和文本信息得以充分利用。值得注意的是,为替代CLIP捕获全局特征,我们引入可学习的CLS令牌,与LLM生成的嵌入结合后输入细化器进行交互,从而有效捕获全局语义信息。
与直接使用预训练多模态大模型(如Qwen-VL)的方法不同,Ovis-U1从预训练的语言模型(LLM)出发,经过多阶段的训练,使模型拥有卓越的多模态理解与生成能力。Ovis的训练流程共分为6个阶段,每个阶段都为模型的最终表现奠定了坚实的基础。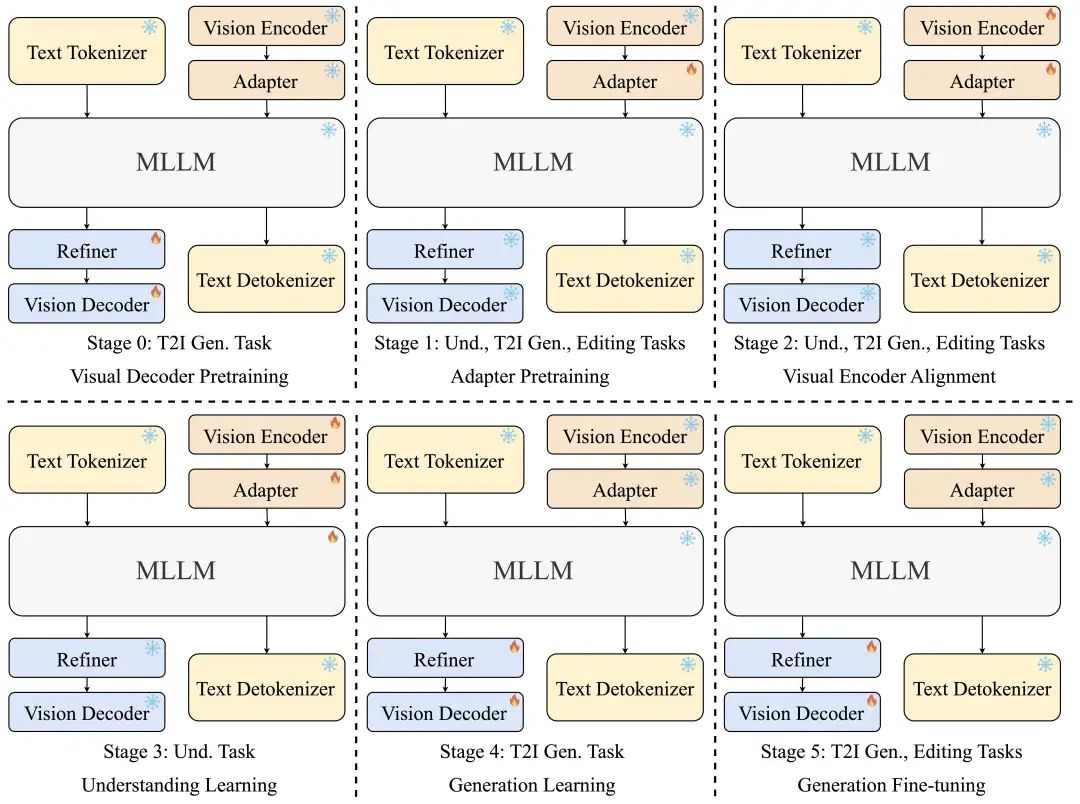
阶段0:视觉解码器预训练
我们从零开始构建了一个拥有十亿参数的扩散变换器作为视觉解码器,阶段0旨在让其拥有基本的图像生成能力。在这个阶段,我们使用文生图的训练数据,使视觉解码器可以根据LLM的嵌入生成图像。
阶段1:适配器预训练
适配器作为视觉编码器和LLM之间的桥梁,对齐视觉和文本嵌入。适配器在此阶段从随机初始化开始训练。与Ovis仅用理解任务训练不同,Ovis-U1同时使用理解、文生图和图像编辑任务进行训练。
阶段2:视觉编码器对齐
此阶段对视觉编码器和适配器进行微调,以进一步对齐视觉和文本嵌入。与阶段1类似,此阶段使用所有三种任务进行训练,我们发现生成任务有助于对齐不同模态的嵌入。
阶段3:理解学习
这一阶段使用理解任务进一步训练视觉编码器、适配器和LLM的参数,进一步激发模型的多模态理解能力。完成此阶段后,这些参数会被固定,以保留理解能力。
阶段4:生成学习
由于阶段3调整了LLM参数,我们随后训练细化器和视觉解码器,使其与优化后的文本和图像嵌入对齐。实验表明,与阶段0相比,经过阶段1-3的优化,文本生成图像的性能显著提升。
阶段5:生成微调
借助模型的文生图能力,最后一个训练阶段对视觉解码器进行微调,以增强文生图、图像编辑等各种生图任务的表现。 通过这些精心设计的训练阶段,Ovis-U1不仅在多模态理解上表现出色,还在图像生成和图像编辑能力上超越了许多特定任务的模型。
作为统一的多模态理解与生成模型,Ovis-U1既能理解输入图像,又能生成图像,拥有图像理解能力、根据文本生成图像能力、图像编辑能力。
下图展示了Ovis-U1在理解和分析复杂视觉内容时的卓越表现。它能够识别精细的细节,例如物体属性、空间层次和微妙的互动,并在特定领域任务中保持上下文意识。这种能力使得Ovis-U1在处理需要深度视觉分析的任务时如鱼得水。
针对多模态理解任务,我们使用OpenCompass多模态学术基准测试Ovis-U1。与目前3B参数范围内的领先模型相比,Ovis-U1显著领先,展示了非凡的理解能力,树立了新的性能标杆。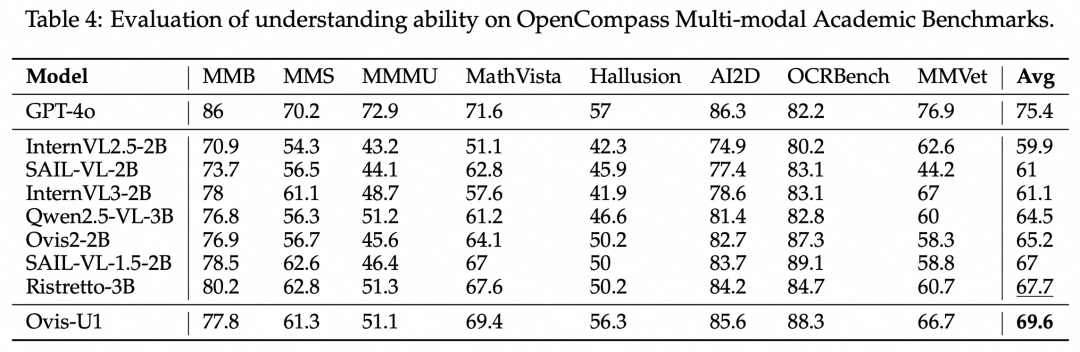
下图展示了Ovis-U1生成高保真图像的能力。无论是逼真的场景、抽象概念还是混合设计,Ovis-U1都能合成引人注目的图像,同时保留复杂的纹理。即便是在处理涉及多物体排列、空间约束或抽象属性绑定的复杂提示时,它也表现出色。
我们使用业界常用的GenEval测试根据文本生成图像的能力。与近期的开源模型相比,Ovis-U1表现亮眼,不仅远超模型尺寸相近的OmniGen模型,同时达到与更大模型相当的性能。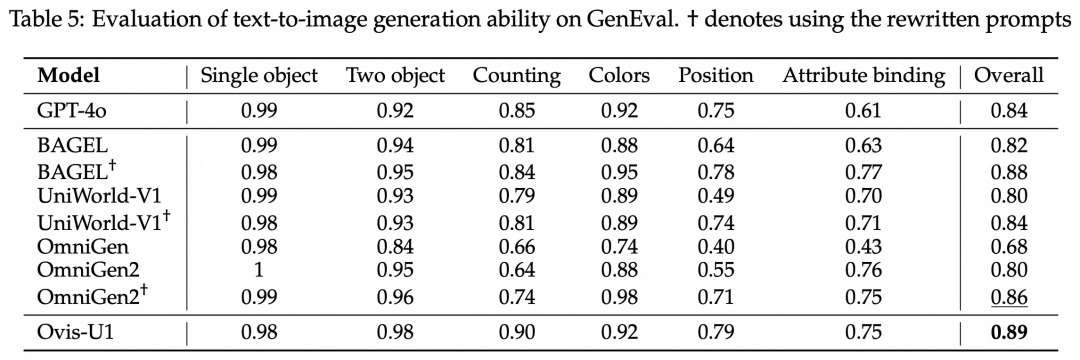
此外,下图展示了Ovis-U1进行编辑图像的精确度。无论是内容替换、风格转换还是结构编辑,它都能在保持背景完整性的同时,严格执行指令提示,生成几乎无瑕疵的结果。
我们使用最近的ImgEdit-Bench测试Ovis-U1的性能。与之前的开源模型相比,Ovis-U1表现出色,它不仅能够进行细致的图像修改,还能保持图像的整体性,在速度和质量上都优于其他竞争对手。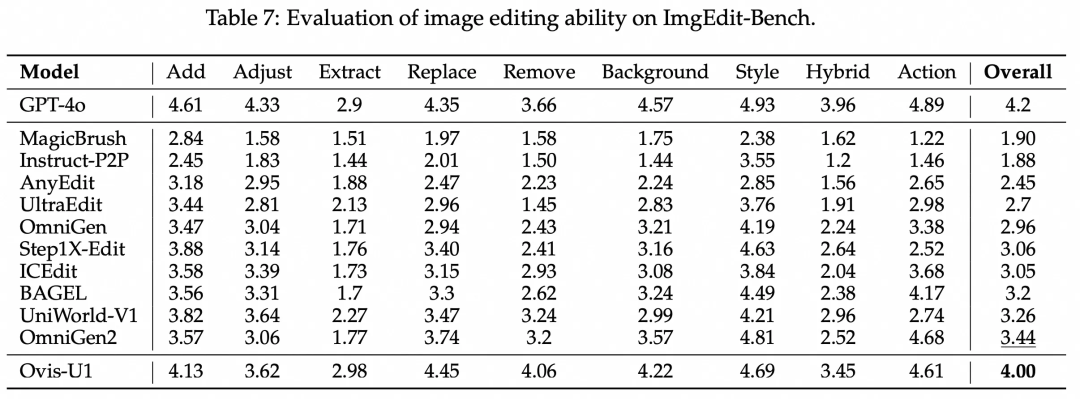
更多的定量评估结果(如DPG-Bench, GEdit-Bench)请参见我们的技术报告。
这些定量评估与之前展示的定性结果相结合,使Ovis-U1成为多模态理解生成任务的多面手。其紧凑的3.6 B参数架构在效率和可扩展性之间实现了良好平衡,不仅为更大规模训练提供了潜力,也保持了实际部署的可行性。
由于模型尺寸相对较小,Ovis-U1仍存在一些局限。在多模态理解方面,Ovis-U1在展现深度思考能力上稍显不足。在图像生成方面,Ovis-U1有时会出现幻觉和伪影现象,生成图像的细节仍有较大的提升空间。此外,Ovis-U1的训练数据仅限于英文,其在中文指令遵循方面的能力也有待进一步提高。
Ovis-U1在模型设计与训练策略上的创新,实现了多模态理解与多模态生成的统一,在技术突破的同时,显著提升了全球用户的体验与创作效率。面向未来,Ovis-U1将持续迭代升级,以应对更多挑战和机遇,主要方向包括:
1.模型参数扩展:进一步训练更大规模参数的Ovis-U1模型,以有效缓解小模型常见的幻觉与伪影问题,带来更高质量的图像生成能力。
2.训练数据优化:训练数据构建链路将持续优化,聚焦多样化、高质量的数据集采集与策划,尤其是大规模图文交织内容,为统一模型的高效训练提供坚实基础。
3.架构创新设计:持续推进架构创新,针对统一多模态任务进行个性化设计。视觉编码-解码结构将进一步优化,在保留图像细粒度信息的同时,实现与大语言模型特征的高效对齐。
4.统一强化学习探索:强化学习技术已成为大模型优化的重要工具。围绕多模态理解与生成的统一模型,亟需探索更有效的对齐人类偏好的强化学习方法,这也是当前领域面临的重要研究课题。
后续,Ovis-U1将在多模态大模型领域持续探索,助力人工智能技术的进一步发展与应用落地。
 京公网安备11010502056287号
京公网安备11010502056287号