
这个消息表面上很简单:NVIDIA 给出一套参考人形机器人方案,身体来自宇树 H2 Plus,手来自 Sharpa Wave,机载计算用 Jetson Thor,上层开发工作流接 Isaac GR00T。

如果这个流程跑顺了,未来研究者拿到的会是从机器人本体延伸出来的技能开发入口。


我会把这件事先放到一个更大的背景里看。
过去两年,人形机器人公司发产品,大家最关心的是本体:多高、多重、能跑多快、能不能抗踹、能不能拿东西。这个阶段当然重要,因为没有足够好的硬件,后面所有算法都很难落地。
但走到今天,只讲本体已经不够了。
一个研究团队真正要把人形机器人用起来,还要处理一堆很碎的东西:机器人怎么接入开发环境,遥操作数据怎么采,仿真资产怎么对齐,策略怎么训练,模型怎么评测,最后怎么部署到真机上。
这套链路如果每个团队都从零搭一遍,人形机器人研究会非常慢。
所以NVIDIA这次推参考设计,我觉得重点在“参考”两个字。它的核心动作,是告诉研究者:以后可以围绕这套硬件和软件接口去做实验。
这件事有点像早期深度学习里的标准GPU服务器、自动驾驶里的参考计算平台。它不一定直接决定谁最后赢,但它会影响很多团队默认从哪里开始。

这次被放进参考设计的,是Unitree H2 Plus。
按照宇树新闻稿里的信息,H2 Plus 是面向学术研究的人形机器人参考设计,接入了 Sharpa Wave 触觉五指手、Jetson Thor 机载计算和 Isaac GR00T 工作流。宇树还提到,H2 Plus 预计会在2026年底开放,GR00T面向Unitree G1 的参考流程也会后续在GitHub和Hugging Face上给开发者使用。
这对宇树来说,意义远超过多卖一台机器人。
更关键的是:如果大量高校和研究机构开始围绕 H2 Plus / G1 做 GR00T 相关实验,宇树就有机会成为人形机器人研究里的默认身体入口之一。
默认身体入口很重要。
因为机器人算法和硬件本体绑定得太深了。一个策略在某个本体上跑通,后续数据、代码、仿真环境、评测脚本都会自然围绕这个本体沉淀。时间久了,生态会自己长出来。
这里也要解释一个经常被问到的问题:为什么是H2 Plus 这种大人形?G1 不也能做研究吗?
我会把它们放在两个位置上看。G1更适合低成本算法验证、社区扩散和快速迭代。它体量小、门槛低,很多实验室拿它做运动控制、强化学习、遥操作和基座模型实验都很合理。宇树新闻稿里也提到,GR00T 面向 G1 的参考流程后面会开放。
H2 Plus 对应的是另一层问题:真实人类尺度任务。桌面、货架、门把手、箱子、工作台高度,本来就是按人类身体尺度设计的。大人形的意义,核心在真实任务尺度:身高、臂展、负载、五指手和机载计算空间,都更接近未来部署时要面对的物理环境。
所以我会把G1看成研究和快速迭代入口,把H2 Plus 看成全尺寸任务验证平台。前者降低参与门槛,后者把系统推向更接近真实应用的尺度。

当然,这还不能说明宇树已经锁定胜局。参考设计只是入口,不等于真实场景里的规模化部署。但对一个机器人公司来说,被放进 NVIDIA 的研究参考栈里,至少说明它不再只是“硬件供应商”的位置。
它开始进入数据、仿真、训练、部署这条更长的链路。


这套参考设计里还有两个细节,我觉得不能略过:Sharpa Wave五指手和Jetson Thor。
很多人看人形机器人,第一眼还是看走路、跑步、跳跃、抗扰。但如果 NVIDIA 把它定义为面向研究的参考人形机器人,只做 locomotion 显然不够。
人形机器人真正进入通用任务以后,迟早要走到移动操作:走过去、看见物体、伸手、接触、抓取、搬运、放置、失败后重新调整。
这里面,“手”承担的是接触入口。
如果没有触觉和灵巧手,机器人很难把世界理解成可以交互的对象。视觉可以告诉它杯子在哪里,语言可以告诉它要拿杯子,但真正接触时,力、滑移、摩擦、握持稳定性,都会变成底层问题。
所以Sharpa Wave 的加入,说明这套参考设计的野心已经从“会走”延伸到全身移动操作。
Jetson Thor 的位置也类似。
机器人上机载计算不只是“算力更强”。它对应的是部署态问题:模型不能永远躺在云端或者实验室工作站里,策略推理、传感器处理、控制闭环,最后都要回到机器人身上。
身体、手、机载计算同时被放进参考设计里,说明NVIDIA 想做的是一套能从训练走向部署的闭环。

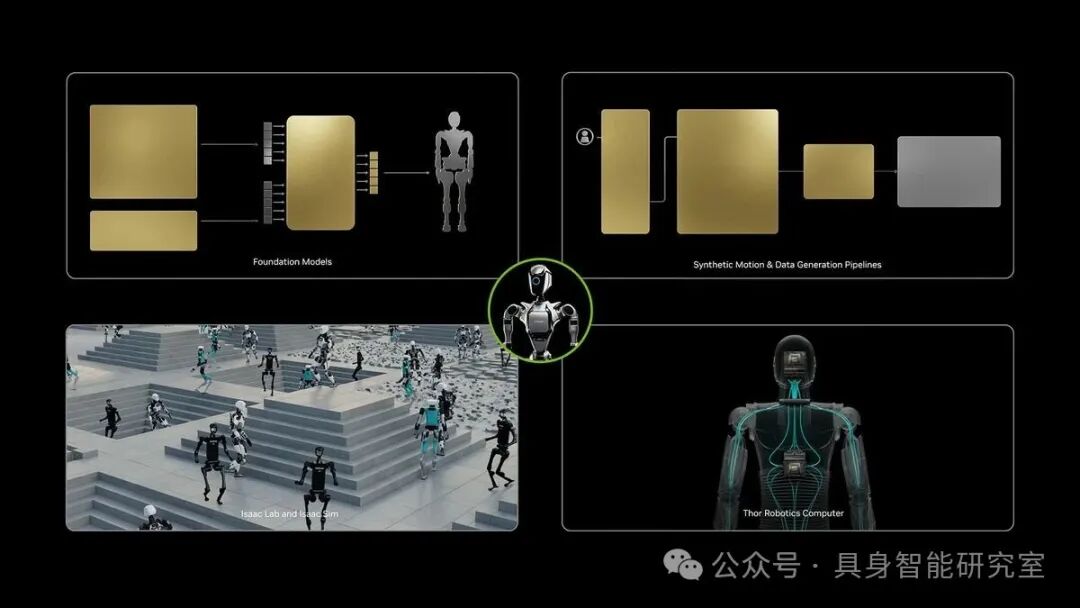
我最近一直在看仿真训练、Sim2Real、CPU/GPU 分工、世界模型和 BFM。把这些线放在一起看,会发现 NVIDIA 这次参考设计背后的主线很清楚:

NVIDIA 官方把 Isaac GR00T 平台描述成覆盖数据采集与生成、模型评测和部署的开发平台。宇树新闻稿里也列出了几个关键模块:Isaac Teleop负责采集高质量示教数据,Isaac GR00T 开放基础模型支持推理和多任务行为,Isaac Sim 和 Isaac Lab 用来仿真、训练、测试和评估策略,Isaac ROS 负责把训练好的策略部署到机器人上,Jetson Thor 负责真机端推理和控制。
这其实就是一条机器人学习流水线。
前面采数据,中间训练和评估,后面部署到真机,再回到真实场景验证。这个闭环如果打通,研究者就不用每次都重新搭数据管线、仿真环境和部署链路。
我前面写UniLab时提到过一个判断:机器人强化学习的训练效率,不能只盯着仿真器每秒能跑多少步。很多时候,整套系统怎么组织,比单个仿真后端跑得多快更关键。
放到NVIDIA 这件事上,也是同一个逻辑。
单点能力当然重要,但真正能让行业加速的,往往是把硬件、数据、仿真、训练、评测、部署放进同一套系统里。

我觉得这里有两个信号。
第一,国内人形机器人公司不能只卷本体参数了。
跑得快、站得稳、抗扰强,这些当然还会继续卷。但如果未来研究者和开发者真正选择一台机器人,判断标准会从机械结构扩展到仿真资产、开源接口、数据工具链、训练框架和部署流程。
硬件公司如果只给本体,不给工具链,开发者会很痛苦。
第二,NVIDIA 正在把自己放到人形机器人生态的中间层。
它不一定自己造机器人,但它可以提供机载计算、仿真平台、训练框架、基础模型和部署中间件。只要这些接口被大量团队采用,NVIDIA 就会越来越像人形机器人时代的“训练栈供应商”。
这对国内团队既是机会,也是压力。
机会在于,标准化参考设计会降低研究门槛,让更多团队能快速验证想法。压力在于,如果核心训练栈长期被外部生态定义,国内公司未来可能会在接口、数据格式、仿真资产和部署链路上越来越被动。
所以我更希望看到国内厂商后面发布机器人视频之外,也能把工具链、数据集、仿真环境、部署接口一起做出来。


这次 NVIDIA 和宇树的合作,我不想简单写成“宇树被 NVIDIA 选中”。
更准确的说法是:NVIDIA 正在把人形机器人研发从单点 demo 往参考系统推,宇树 H2 Plus 成了这套系统里的关键身体入口。
这件事短期不会立刻改变产业格局。H2 Plus 还要等到2026年底,GR00T 面向 G1的参考流程也还在等待正式开放。真正能跑出多少高质量研究,还要看后续社区使用情况。
但方向已经很清楚了。
人形机器人进入下一阶段后,单靠一个好看的运动视频不够,单靠一个强模型也不够。谁能把数据采集、仿真训练、模型评测、机载部署和真实验证组织成一条稳定流水线,谁就更有机会把demo变成可复用能力。
这才是我觉得这件事值得写的原因。
它更像一个提醒:人形机器人行业正在从“谁的机器人更像人”,走向“谁能把机器人训练成系统能力”。
 京公网安备11010502056287号
京公网安备11010502056287号